名字粉碎
名字粉碎(Name Mangling,也称为名字修饰) 是编译器为解决命名冲突(如函数重载、类成员、命名空间、模板等场景)而对标识符(函数名、变量名等)进行的特殊编码处理。其核心目的是生成唯一的符号名,确保链接阶段能准确识别不同的实体。
C 语言不支持函数重载、类、命名空间等特性,函数名本身即可唯一标识一个函数,因此无需修饰。但 C++ 支持以下特性,会导致同名实体存在,必须通过名字粉碎区分:
- 函数重载:允许同名函数存在,只要参数列表不同(参数类型、数量、顺序);
- 类成员函数:不同类中可以有同名成员函数;
- 命名空间:不同命名空间中可以有同名实体;
- 模板:模板实例化会生成不同的具体函数 / 类,需区分模板参数。
修饰名由函数名、类名、调用约定、返回类型、参数等共同决定。
调用约定
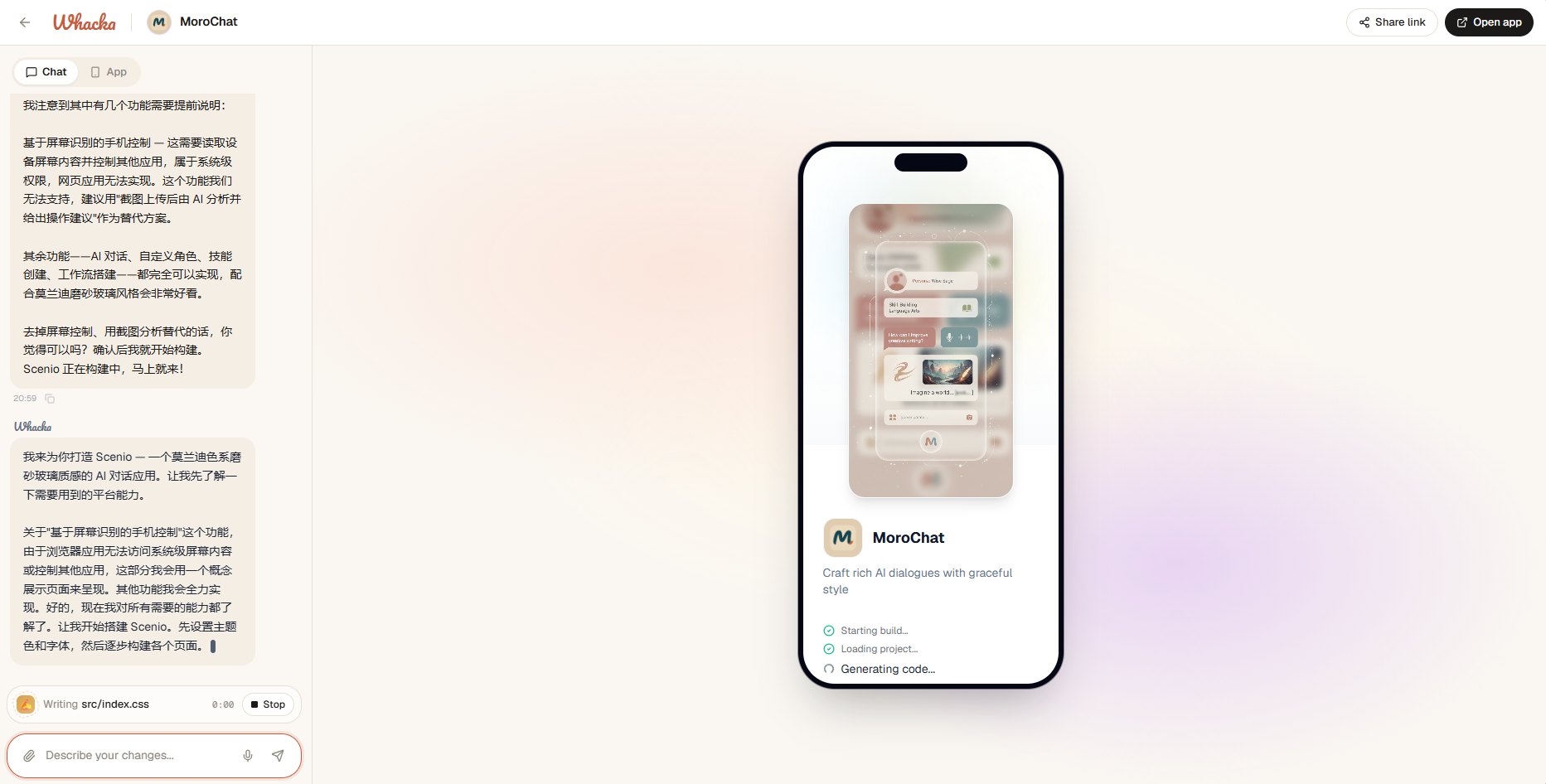
__stdcall(回调调用约定)是Pascal程序的缺省调用方式,通常用于Win32 API中,函数采用从右到左的压栈方式,自己在退出时清空堆栈
1 | void __stdcall funa(int a, int b) {} //回调调用约定 |
栈平衡:funa首先压2,1入栈,ESP上抬8,当函数退出后ESP需要回退到起点,由被调用函数维持
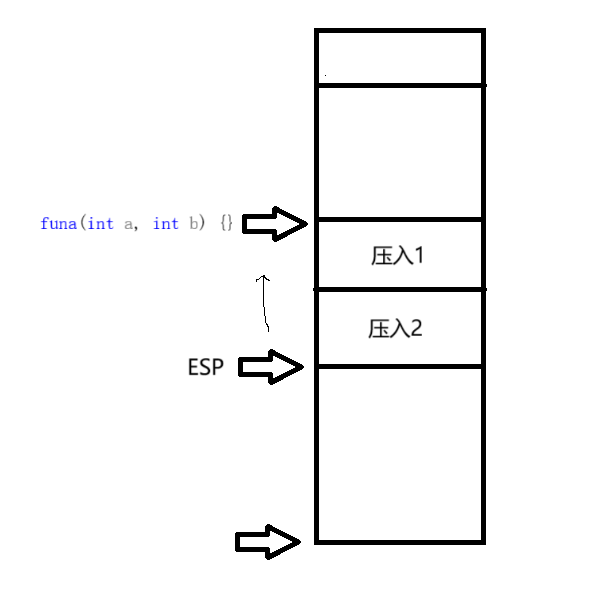
__cdecl(C调用约定)即用关键字说明)按从右到左的顺序压参数入栈,由调用者把参数弹出.对于传送参数的内存栈是由调用者来维护的,正因如此,实现可变参数的函数只能使用该调用约定
1 | void __cdecl funb(int a, int b) {} //C调用约定 |
__fastcall(快速调用约定)主要特点就是快,因为其是通过寄存器来传参的(实际上他使用ECX和EDX传送前两个双字(DWORD:在 x86 架构(32 位)中,“双字” 指 32 位(4 字节)的数据类型,如int、unsigned int、long(32 位环境下)、指针(32 位地址)等)或更小的参数(指尺寸小于 32 位的数据类型,如 8 位的char、16 位的short等),剩下的参数仍旧自右向左压栈传送,被调用的函数在返回前清理传送参数的内存栈),在函数名修饰约定方面,他与前两者均不同
1 | void __fastcall func(int a, int b) {} //快速调用约定 |
在 x86 架构的通用寄存器(
EAX、EBX、ECX、EDX、EBP、ESP等)中,ECX和EDX被选中主要是因为它们的 “通用性”—— 没有被赋予必须固定承担的特殊职责:
EAX:常用于返回值存储(函数返回时默认用EAX传递返回值),若占用可能冲突;EBX:在某些编译模式下被用作 “基址寄存器”(如全局数据访问),需保持稳定;EBP:栈基址指针,ESP:栈顶指针,两者用于维护栈帧结构,绝对不能用于传参;ECX、EDX:无强制固定用途,且在 x86 指令集中常用于通用计算(如ECX可作为循环计数器),用作参数传递寄存器不会与其他核心功能冲突。
1 | int main() { |
| 调用约定 | 参数传递顺序 | 栈清理者 | 支持可变参数 |
|---|---|---|---|
__cdecl |
右→左 | 调用者 | 是 |
__stdcall |
右→左 | 被调用者 | 否 |
__fastcall |
前 2 个用寄存器,剩余右→左 | 被调用者 | 否 |
thiscall仅用于C++类成员函数,this指针存放于ECX寄存器,参数从右到左压入,thiscall不是关键字,因此不能被程序员指定
Name Mangling是一种在编译过程中将函数名,变量名的名字重新命名的机制
C语言编译时的函数名修饰约定规则
C语言的名字修饰规则十分简单,__cdecl是C/C++的缺省调用方式,调用约定函数名字前添加了下划线前缀:_functionname
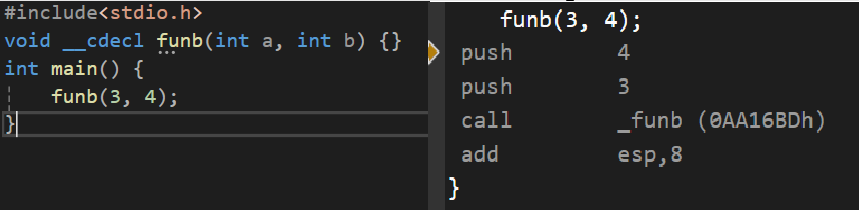
__stdcall(标准调用约定)在函数名前加下划线_,后加@和参数总字节数(十进制),例如void foo(int a, int b)(参数共 8 字节)修饰后为_foo@8。
C++编译时的函数名修饰约定规则
__cdecl调用约定
- 以
?标识函数名的开始,后跟函数名 - 函数名后以
@@YA标识参数表的开始,后跟参数表 - 参数表以代号表示
基础数据类型
| 类型 | 代号 | 说明 |
|---|---|---|
void |
X |
无类型(用于无参数或返回 void) |
char |
D |
8 位字符型 |
signed char |
C |
有符号 8 位字符型(与char可能不同,取决于编译器是否默认signed) |
unsigned char |
E |
无符号 8 位字符型 |
short(short int) |
F |
16 位有符号整数 |
unsigned short |
G |
16 位无符号整数 |
int |
H |
32 位有符号整数(最常用,如int a的参数代号为H) |
unsigned int |
I |
32 位无符号整数 |
long(long int) |
J |
32 位有符号长整数(32 位环境下与int长度相同,64 位可能为 64 位) |
unsigned long |
K |
32 位无符号长整数 |
long long |
Q |
64 位有符号长整数(__int64) |
unsigned long long |
R |
64 位无符号长整数 |
float |
M |
32 位单精度浮点数 |
double |
N |
64 位双精度浮点数(如double b的参数代号为N) |
long double |
O |
扩展精度浮点数(通常 80 位或 128 位,取决于编译器) |
bool |
_N |
布尔类型(1 字节或 4 字节,MSVC 中通常为 4 字节) |
复合类型(指针、引用、数组等)
| 类型 | 代号规则 | 示例 |
|---|---|---|
指针(T*) |
前缀P + 基础类型代号 |
char* → PAD(P+A+D,A为指针修饰);int* → PAH |
引用(T&) |
前缀A + 基础类型代号 |
int& → AH;double& → AN |
数组(T[]) |
前缀$ + 元素类型代号 + 数组长度(可选) |
int[3] → $H3;char[] → $D(未指定长度) |
| 函数指针 | 前缀P6 + 返回类型 + 参数表 + @Z |
int(*)(char) → P6HAD@Z(P6为函数指针标记,H返回 int,D参数 char) |
类 / 结构体 / 命名空间类型
| 类型 | 代号规则 | 示例 |
|---|---|---|
类 / 结构体T |
前缀V + 类名 + @@ |
类A → VA@@;结构体S → VS@@ |
类指针(T*) |
P + 类类型代号 |
A* → PVA@@(P+VA@@) |
| 命名空间中的类型 | 命名空间名 + @ + 类型代号 |
命名空间ns中的类B → Vns@B@@ |
1 | "bool __cdecl Namefuna(int,int)" (?Namefuna@@YA_NHH@Z) |